

수식이 틀어지는 경우, 수식에 우클릭을 하고 math setting -> math renderer -> SVG를 선택 후 새로고침 바랍니다 : )
Graph-based SLAM
4.1 Problem formulation
아래 사진은 모바일 로봇이 미지의 환경을 돌아다니며 자신의 이동을 추정하고 물체를 탐지하는 SLAM에서의 한 상황이다.

그렇게 만든 지도는 로봇 자신이 어디있는지 아는 데 사용된다.
이를 graph 로 구성된 관계로 그려보면 다음과 같다.
이 그림은 실제 로보틱스에서 localization과 mapping 문제를 잘 나타낸다.
왼쪽은 물체의 상대적인 위치와 방향을 그려놓은 것이다.
오른쪽은 왼쪽과 같은 상황에 대해서 edge와 node인 그래프로 표현한 것이다.
파란색인 edge는 motion에 대한 측정값을 나타낸다.
빨간색은 물체의 측정값을 나타낸다.
4.1.1 SLAM as a Dynamic Bayes Network
과정은 dynamic Bayes network(DBN)으로 잘 나타낼 수 있다.
DBN은 확률론적 그래픽 모델(통계모델의 일종)이다.
DBN은 확률론적 방향 비순환 그래프를 통해 랜덤 변수 집합과 그들의 조건부 의존성을 나타낸다.
조건부 의존성은 방향을 가진 화살표로 두 개의 변수를 연결한다.
그래프에서
비순환적인 속성은 '
우리의 경우 네 가지의 랜덤 변수가 존재한다.
- 모든 로봇의 state,
- 모든 랜드마크의 state,
- 모든 로봇의 controls,
- 모든 랜드마크의 measurements,
섹션 2.3에서 나온 것처럼 로봇의 motion controls 때문에 시간
이 motion model을 다음과 같이 쓸 수 있다.
그리고 이것은
비슷하게, 환경에 대한 각각의 측정값도 아래와 같이 모델링 될 수 있다.
이것은 환경에 대한 맵
서브 그래프를 합하면 Fig 4.2의 왼쪽에 해당하는 DBN이 나온다.
물론 여기서 m은 환경 지도를 나타내는 추상적인 엔티티로, SLAM 프레임워크의 설계에 따라 여러 형태를 취할 수 있다.
흥미로운 부분은 지도가 개별적으로 측정 가능한 랜드마크로 바뀌었을 경우이다.
이런 경우에는 pose
서브그래프 표현은 다음과 같다.
식 4.2에 나온 서브그래프와 식 4.6의 서브그래프를 합하면 Fig 4.2의 오른쪽에 나오는 DBN이 도출된다.
이것은 Fig 1.1에서 나온 상황을 정확히 보여준다.
그림을 보면 각각의 랜드마크가 명확히 보인다.
일반성을 잃지 않고, 랜드마크가 있는 경우에 중점을 둬보자.
이렇게 구성된 DBN은 문제의 모든 변수 간의 모든 종속성을 포함한다.
그것은 그래프에 표시되지 않은 모든 것이 독립적이며 따라서, trajectory, map, controls, measurements의 결합 확률들이 다음과 같이 조건부 곱으로 표현될 수 있음을 의미한다.
마지막으로, SLAM estimator의 목적은 저 확률을 최대화하는 변수인
아래와 같이 나타낼 수 있다.
4.1.2 SLAM as a factor graph
식 4.7의 결합 확률(A와 B가 동시에 발생할 확률)은 4.2와 4.6의 M+K개의 요소의 곱으로 나타낼 수 있으며, 이들은 모두 독립적이다.
이러한 요소들은 각각 적은 수의 state 노드에 의존하는 측정에서 비롯된다.(pose 또는 landmark 혹은 두 개 다 섞인)
따라서 이 그래프를 그러한 요소들을 명시적으로 나타내는 그래프로 변환하는 것이 좋다.
이를 factor graph라고 하며 Fig 4.3을 참고하자.
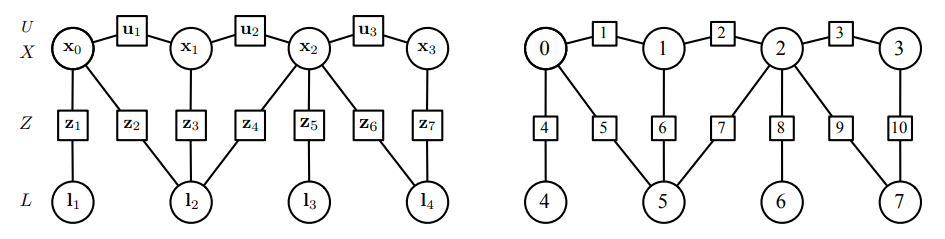
Factor graph는 두 종류의 노드를 가지고 있는 이분 그래프이다.
Variable node들은 로봇의 state를 구성하고 factor node들은 state들 사이에 제약 조건을 구성한다.
인자들은 시스템에 들어오는 모든 정보를 부호화하고 그래프는 이 정보가 우리가 추정하려는 숨겨진 상태로 전달되는 방식을 포착한다.
Factor를 구성하는 조건부 확률(4.2-4.6)은 모션과 측정 모델에 의해 쉽게 알아낼 수 있다.
motion model과 measurement model이 생소하다면 챕터 2와 3을 다시 보는 것을 추천한다.
그 모델들은 다음과 같이 생겼다.
- Robot motion, $\textbf{x}_{i} = f_{i}(\textbf{x}_{i-1},\textbf{u}_{i}) + \textbf{w}_{i}, \textbf{w}_{i} \sim \mathcal{N}
- Landmark measurements, $\textbf{z}_{k} = h_{k}(\textbf{x}_{i_{k}},\textbf{l}_{j_{k}}) + \textbf{v}_{k}, \textbf{v}_{k} \sim \mathcal{N}
모델 내의 noise
만약 우리가 고유한 인덱스 k로 오차 값을
- Robot motion,
- Landmark measurements,
(4.9)와 (4.10)의 factor들은 고유한 형태를 취한다.
이는
우리가 motion과 measurement factor 간에 만든 구별은 그리 중요하지 않다.
그러므로 간소화와 더 큰 일반성을 위해, 이후에는 두 가지 유형의 변수만을 고려한다.
- state to estimate
- observed data
한편으로는, 우리가 추정하고자 하는 states {
여기에서
반면에, 이러한 상태를 연결하면 control과 measurements를 포함하는
그러면 각 관측 데이터
결합확률 (4.7)은 모든 factor의 곱으로 나타낼 수 있다.
PDF(확률 밀도 함수)를 최대화하는 것은 이것의 log-likelihood를 최소화하는 것과 동일하며 이는 cost라고 불린다.
이를 정리하면,
수식을 풀면,
마지막으로 주목해야 할 점은
이는 다음과 같은 형식과 표기를 가진다.
A note on motion errors
이 부분에서 핵심은 error를 measurement space에서 정의하는 것이다.
생각해 보면 우리는 지금까지 motion model을
와 같이 정의했다.
사실 위와 같이 정의한 것은 state space에서의 정의이며 다음과 같은 motion model을 고려하여 나타난다.
하지만 noise
따라서 다음과 같다.
여기에서
로봇의 상태가 제어입력과 상관없이 변경될 수 있는 불확실성을 나타낸다.
로봇의 상태가 제어입력과 직접 적용된다.
이는 다른 말로 제어입력이 정확하지 않음을 의미한다.
그래서 잘 정의된 정보행렬
따라서 error는 다음과 같이 정의한다.
위 식은 예측된 제어입력과 실제 제어 입력의 차이로 error를 정의하는 식이다.
그리고 measurement space에서 정의된 error로 볼 수 있다.
예제로 IMU motion integration과 같은 복잡한 상황을 다루는 것을 제시한다.
여기에서는 modified measurement
landmark measurements,
이렇게 함으로써 복잡한 모션 데이터를 다룰 수 있다.
4.2 Iterative non-linear optimization
잠깐 최적화에 대해 이야기하는 섹션이다.
사실 기본적인 최적화 방법인 가우시안 뉴턴에서 LM방법까지 잘 알고 있다면 생략해도 되는 섹션이다.
자 이제 간단한 기초 내용을 살펴보고 여러 방법을 알아보자.
어떤 cost function
최적의 state
모든 iterateve optimization 방법은 step을 가지고 반복적으로 해에 접근한다.
그 과정에서
4.2.1 The general case and the Newton method
Fig. 4.4에 나온 것처럼 step마다
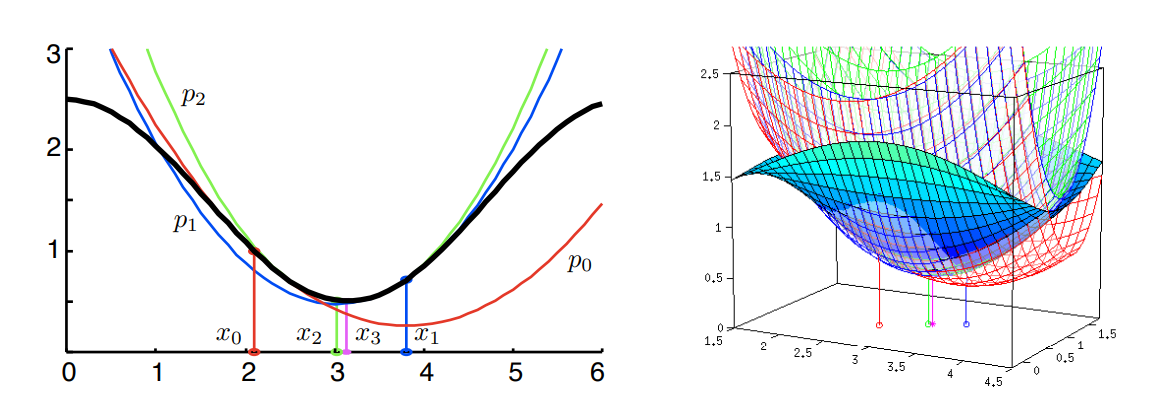
Fig. 4.4는 iterative Newron step을 이용해서 nonlinear optimization문제를 해결하는 과정을 보인다.
검은색의 비선형 함수가 있을 때, 이 함수의 minimum
이렇게 2차 함수로 근사하고 그 최솟값에서 다시 2차함수로 근사하며 점점 해에 다가간다.
오른쪽 figure도 이와 동일한 방법으로 매쉬 형태를 가진 함수로 하는 과정이다.
2차 테일러 전개를 통해 현재 추정치에서 cost의 local parabolic 근사를 다음과 같이 나타낸다.
그리고 최적 스텝
그리고 Newton step을 도출한다.
Newton method는 초기 추정치가 해와 가까우면 빠르게 수렴한다.
초기추정치가 해와 멀면 수렴이 불안정해진다.
또한 두 가지 중요한 단점이 존재한다.
hessian matrix에 대한 개념이 필요하다.
헤세 행렬(Hessian Matrix)의 기하학적 의미 - 공돌이의 수학정리노트 (Angelo's Math Notes)
angeloyeo.github.io
- step의 길이가 긴 경우 local minimum에 빠질 수 있다.
이 경우는
너무 작은 경우는 cost
이럴때 step이 크게 계산되며 최적화가 실패하고 잘못된 지점으로 이동할 수 있다. - 오목한 영역에서의 문제
오목한 영역에서는
즉, 비용을 증가시키는 방향으로 이동하며, 최솟값에서 멀어진다.
이렇게 되면 최적화가 실패한다.
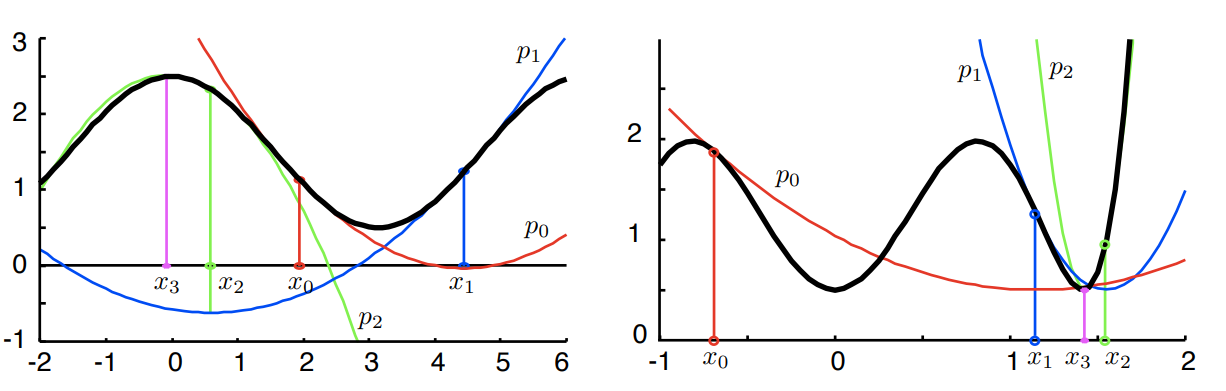
이러한 두 가지 단점은 fig. 4.5 왼쪽 그림에 나와있다(실패 상황).
오른쪽 그림은 안정적으로 수렴하는 과정을 보인다.
4.2.2 The least squares case and the Gauss-Newton method
많은 상황에서 cost function은 error
그렇다면 gradient vector
- 식 (4.32) : 열 벡터
- 식 (4.33) : 1차 도함수의 jacobian matrix
- 식 (4.34) : 2차 도함수의 hessian tensor
Cost에 대한 지역적 이차 근사에 따르면 form은 다음과 같다.
hessian
여기에서 두 번째 항
왜냐하면
계산이 복잡하고 다루기 어려울 수 있는데 덕분에 한결 나아진다.
간소화를 적용하면 Gauss-Newton 의 cost function은 다음과 같다.
Error에 대해 선형 근사를 하면
Gauss-Newton step은
또는 gradient vector
Jacobian
이것으로 step이 observed error
Weighted inverse
- Weighted jacobian
- Approximate Hessian
grammian matrix는 행렬의 열 벡터들의 내적을 통해 만들어진다.
Gaussian 분포의 경우, 행렬
Information matrix는 변수
Gauss-Newton 방법은 Newton 방법과 똑같은 단점을 가지지만 다른점이 있다.
Gauss-Newton 방법에서는 수정된 헤시안 행렬
Hessian matrix가 항상 양수이니까 곡률에 대한 정보는 최솟값밖에 없다는 뜻이다.
나머지 단점은 위에서 언급한 Newton 방법에서와 동일하다 : )
4.2.3 Improving convergence with the Levenberg-Marquardt(LM) algorithm
앞서 살펴본 Newton-based 방법들은 다음과 같은 단점을 가지고 있었다.
- 초기값이 최적에 가까운 경우에 효과적이다.
- 최적점에서 멀어지면 근사한 포물면이 최소값의 형태에 맞지 않고 계산된 step이 부적절할 수 있다.
- Hessian matrix의 곡률이 작으면, step이 매우 커지며 최적화가 불안정해질 수 있고 최적값에서 멀어질 수 있다.
LM 알고리즘은 Levenberg의 idea를 Marquardt가 보완한 것이다.
최적 해로부터 멀리 떨어져 있을 때 gradient decent 방법으로 접근하고 최적 해 근처에서는 Gauss-Newton 방식으로 동작한다.
Gauss-Newton보다 안정적인 수렴을 보여주기 때문에 비선형 최적화 문제에서는 일반적으로 많이 사용된다고 한다.
한 번 살펴보자.
Levenberg
Levenberg의 key idea는 Hessian에 damping(감쇠)를 줘서 Gauss-Newton step을 수정했다는 것이다.
여기에서
파라미터
Marquardt
Marquardt는 Levenberg 아이디어의 damping matrix를 identity matrix
이렇게 함으로써 비용 함수의 곡률에 따라 상태의 각 방향에 다른 감쇠를 적용한다.
4.2.4 The sparse structure of the SLAM problem
작성중...
추가 내용 작성 중
24.6~
본 내용은 Joan Sola님의 Course on SLAM의 내용을 주로 참고하여 작성했습니다.
[reference]
1. 다크프로그래머
함수최적화 기법 정리 (Levenberg–Marquardt 방법 등)
※ 참고로, 아래 글 보다는 최근에 올린 [기계학습] - 최적화 기법의 직관적 이해를 먼저 읽어볼 것을 추천합니다. 그 이후에 아래 글을 읽어보시면 좋을 것 같습니다. ---------- 원래는 Levenberg-Marqu
darkpgmr.tistory.com
오류가 있다면 댓글을 남겨주세요~
'연구 > SLAM 기본' 카테고리의 다른 글
| LiDAR point cloud 시각화 (0) | 2024.05.11 |
|---|---|
| [용어 정리]Multi-Modal Neural Radiance Field for Monocular Dense SLAM with a Light-Weight ToF Sensor (1) | 2023.10.10 |