

Don't Hit Me
개인 연구와 관련된 논문을 조사하던 중 발견했으며 흥미로운 주제를 가지고 문제를 풀어나간다.
오직 한 장의 RGB이미지를 가지고 어떻게 유리를 검출해 낼 수 있을지 궁금했다.
여기서 쓰인 contexture information을 개인 연구에 적용할 수 있겠다고 생각했다.
깃헙은 아래 있다.
Issue를 살펴보니 custom dataset의 경우 성능이 좋게 나오지 않나보다.
좋은 결과가 아니니 그냥 스윽~ 훑어보자
GitHub - Mhaiyang/CVPR2020_GDNet
Contribute to Mhaiyang/CVPR2020_GDNet development by creating an account on GitHub.
github.com
0. Abstract
목표 : 한 장의 RGB 이미지로부터 유리를 검출하는 것.
저자가 이 논문에서 제시한 contributions.
- GDD(large-scale glass detection dataset)
- GDnet(a glass detection network)
- LCFI(large field contextual feature integation)
1. Introduction
저자는 유리 감지가 왜 필요한지 문제를 정의한다.
우리가 흔히 생각하는 것과 같다.
AI시스템(로봇, 드론 등)에게 있어 유리라는 것은 위험 요소이기 때문이다.
vision과 lidar task에서도 항상 어려움을 안겨줬다.
컵과 와인잔과 같이 고정된 패턴이 존재하는 경우 기존의 방법으로 detection에 무리가 없었다.
하지만 유리는 위와 같은 고정된 패턴이 존재하지 않거니와 유리 뒤쪽에 위치하는 물체들의 복잡함 때문에 인식에 난항을 겪어왔다.
이런 문제를 해결하기 위해서 저자는 low-level과 high-level cues라는 단어를 언급한다.
low-level cues는 유리 안쪽과 바깥쪽의 색 차이, 유리의 반사에 의한 번짐이나 고스트 현상을 의미한다.
high-level contexts는 물체들 끼리의 관계를 의미한다.
이는 어떻게 보면 인간이 유리임을 추론하는 과정과 비슷한 맥락을 가진다.
주변의 풍부한 정보를 이용해서 추론하는 것이다.
2. Related Work
간단히만 짚고 넘어간다.
- Semantic/scene/instance segmentation
- Salient object detection(SOD)
- Specific region detecetion/segmentation
- Single image reflection removal(SIRR)
3. A New Dataset for Glass Detection - GDD
저자는 GDD라는 새로운 데이터셋을 만들었다.
이름은 large-scale glass detection dataset(GDD)이다.
GDD는 3916개의 (이미지, 마스크)쌍으로 이루어져 있다.
대략 3:1의 비율로 실내 실외에 대한 이미지다.
여기에서 데이터 셋을 만들면서 어떤점을 고려하며 데이터를 구성했는지 들여다볼 수 있다.


- Glass type
fig 3(a)를 보면 어떤 오브젝트로 데이터셋이 구성되었는지 알 수 있다.
추후 scene understanding을 위해 glass object도 추가되어 있다.
Fig 2에보면 다양한 물체가 어떤 식으로 데이터셋에 들어가 있는지 데모를 볼 수 있다. - Glass location
fig 3(b)를 보면 유리의 영역이 여러 군데로 있지만 주로 중심에 잘 모여 있음을 알 수 있다. - Glass area
fig 3(c)와 fig 3(d)를 놓고 비교한다.
두 분포도는 감지 대상이 이미지에서 차지하는 비율을 가져다 만들어 놓은 분포이다.
fig 3(c)는 GDD의 분포이며 fig 3(d)는 MSD(mirror segment dataset)의 분포이다.
GDD가 더 넓은 영역을 커버하는데, 여기서 (0.8, 1.0) 구역은 유리와 정말 근접한 상황을 나타낸다.
그런 경우, 유리 건너편의 물체들만의 관계가 남는데 이는 어려운 문제가 된다.
즉, small object로부터 평범한 유리, 완전 근접하여 유리 건너편 물체만 보이는 상황 등 다양한 시나리오를 가진다는 뜻이다.
4. Methodology
방법의 키 컨셉은 Introduction에서 이미 말했던 low-level cues, high-level contexts이다.
결국 인간이 유리를 추론하는 것처럼 이를 딥러닝 아키텍처로 추론하는 것이다.
이를 위해서 새로운 LCFI를 제안한다.
두 번째, 다양한 사이즈의 유리를 감지하기 위해서 multi-scale large-field contextual feature를 효율적으로 통합하기 위한 새로운 LCFI모듈을 제안한다.
세 번째, 다양한 장면에서 강인한 유리 감지와 다양한 레벨에서의 large-field contextual feature를 위해서 다수의 LCFI모듈을 GDnet에 포함시켰다.
4.1. Network Overview
Network의 순서는 번호를 매겨가며 설명하려 한다.
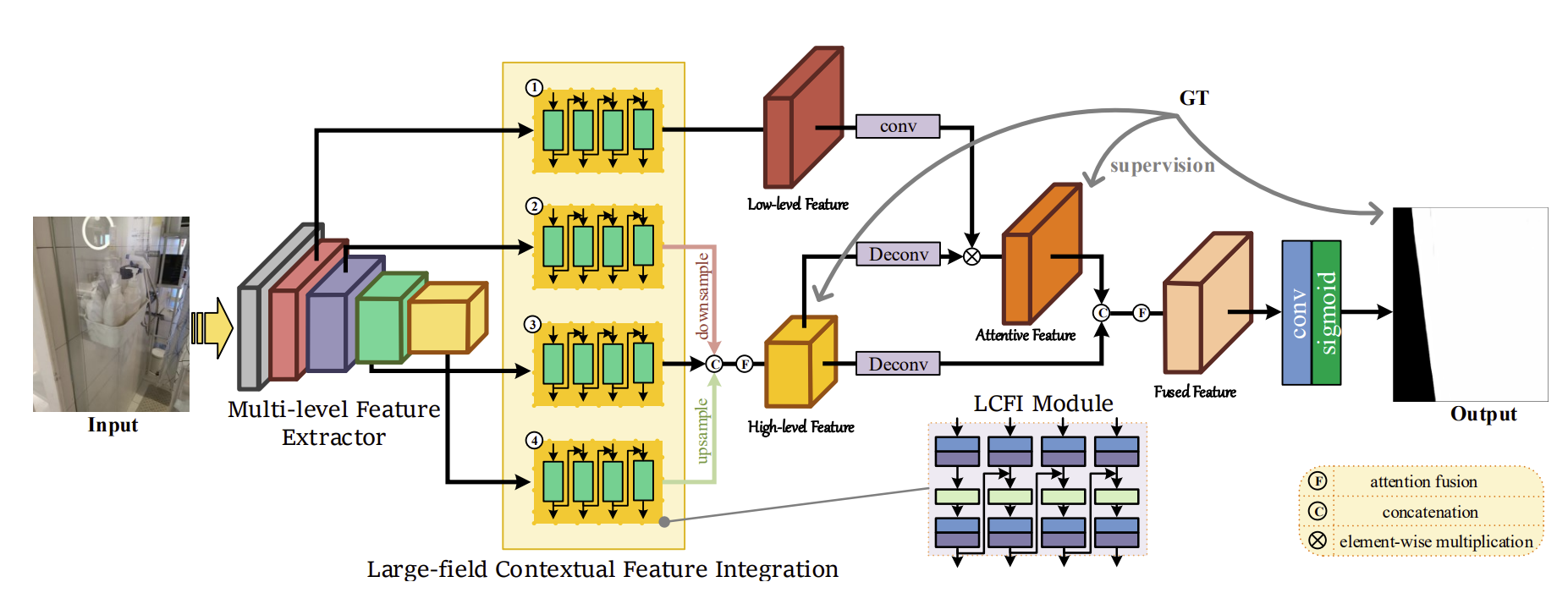
- Multi-level feature extractor(MFE)를 이용해서 여러 레벨에서 feature를 뽑는다.
- 여기에서 나온 feature는 level별로 서로 다른 네 개의 LCFI 모듈을 거친다.
이렇게 해서 large-field contextual features를 학습하게 한다. - 네 개의 LCFI모듈중 2~4번 모듈은 high-level large-field contexture feature를 만든다.
2~4번 모듈의 결과는 1번 모듈이 유리 영역에 더 많이 집중하도록 low-level large-field contextual를 가이드한다. - 마지막으로 유리 감지 결과를 위해 low-level과 high-level의 contexture feature를 fuse 한다.
4.2. Large-field Contexture Feature Integration
아래 fig 5는 LCFI모듈의 구조다.
여기에서 LCFI 모듈은 다른 사이즈의 유리 감지를 위한 목적을 위해 multi-scale large-field contextual features를 효율적으로 추출하고 통합하는 것에 집중한다.
여기에서 Dilated Convolution 개념이 나오는데 혹시 이해가 부족하다면 아래 링크한 포스팅을 참고하면 도움 된다.
딥러닝에서 사용되는 여러 유형의 Convolution 소개
An Introduction to different Types of Convolutions in Deep Learning을 번역한 글입니다. 개인 공부를 위해 번역해봤으며 이상한 부분은 언제든 알려주세요 :)
zzsza.github.io
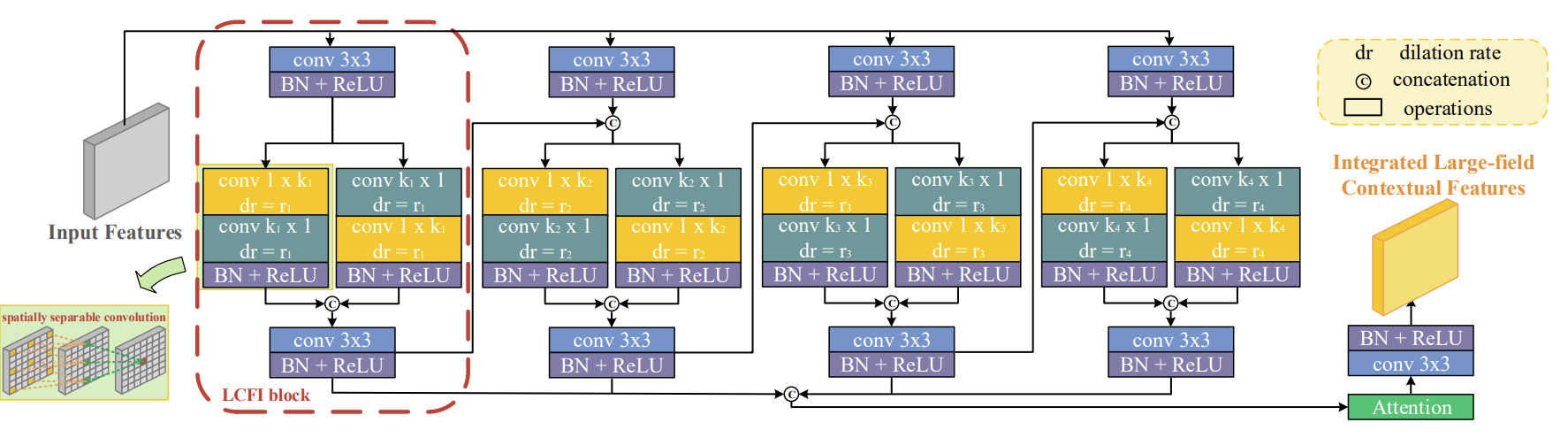
LCFI block
LCFI의 목표를 다시 말하자면 large field에서 풍부한 contextual information을 더 효율적으로 추출하기 위함이다.
따라서 large context information을 얻기 위해서는 더 큰 커널이나 dilated convolution을 사용해야 한다.
하지만 커널 크기가 커질수록 연산 비용이 많이 들고 큰 dilation rate는 sparse sampling을 야기한다.
그래서 저자는 spatialy separable 한 convolution을 제안한다.
Fig 5의 LCFI 블록을 보면서 따라가면 이해하기 쉽다.
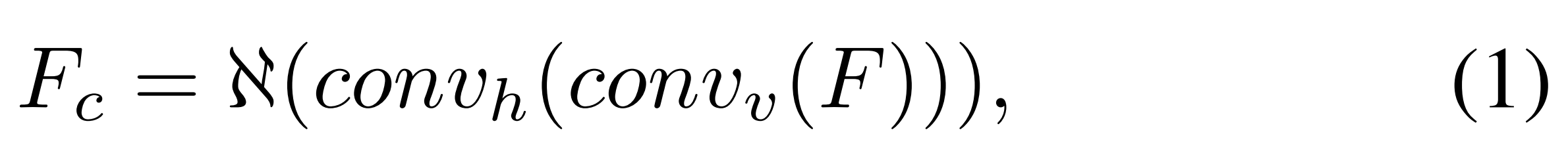
$F$ : input feature
$conv_{h}$ : 수평 컨볼루션 1 x $k$
$conv_{v}$ : 수평 컨볼루션 $k$ x 1
$\mathfrak{N}$ : batch normalization과 ReLU 연산
- reverse convolution : 유리 안쪽의 복잡한 부분의 모호함을 제거하기 위해 contexture feature가 필요하다. 그래서 reverse convolution 순서로된 spatially separable convolution 사용. 위 (1) 식이 이에 해당.
- dilated spatially separable filters : large field 데이터에서 더 많은 contexts를 찾기 위해 사용.
- BN and ReLU : 두 path로 나누어진 contexture feature를 concatenate 하고 3 x 3 convolution, BN and ReLU적용.
결국 LCFI블록은 다음과 같이 정의된다.
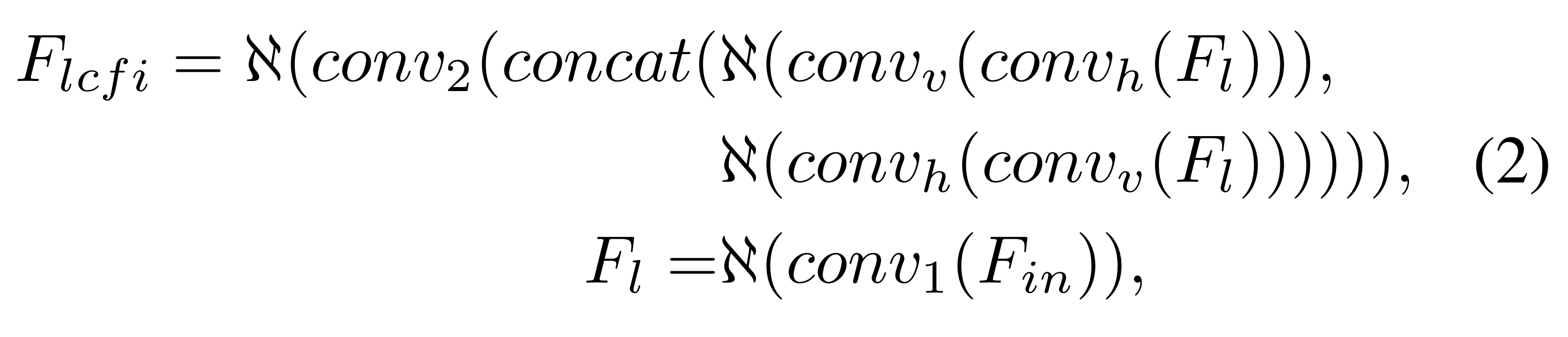
LCFI module
LCFI 블록은 주어진 커널 사이즈 $k$와 dilation rate $dr$을 가지고 large field로부터 contexture feature를 추출했었다.
하지만 다음과 같은 문제점이 있다.
- 만약 이 field가 전체적인 유리 영역을 커버할 정도로 크지 않은 경우, 불완전한 검출이 발생할 수 있다.
- 만약 이 field가 작은 유리 영역을 커버하기에 너~무나도 큰 경우, noise와 FP를 야기할 수 있다.
이러한 경우를 위해서 각기 다른 scale의 context를 고려했다고 한다.
이 것이 LCFI module의 목적이다.
마찬가지로 fig 5를 따라가며 이해하면 좋다.
- input feature가 네 개의 LCFI블록으로 들어간다.
네 블록에 대해서 각각 $k$ : 3, 5, 7, 9 $dr$ : 1, 2, 3, 4로 설정된다.
더 많은 contexture information을 찾기 위해서 인접한 LCFI 블록 사이에 information flow를 추가한다. - 네 개의 블록에서 나온 output을 Attention모듈을 이용해서 fuse 한다.
저자는 LCFI가 ISD 모듈에서 영감을 얻었다곤 하지만 그것과 다름을 설명도 한다.
- 다양한 스케일의 큰 필드에서 contexture information을 탐색하여 다양한 크기의 유리를 탐지하는데 중점을 둠.
- 공간적으로 분리 가능한 convolution을 활용해서 large-field에서 풍부한 contexture information을 탐색.
항상 기존의 방법을 참고했다거나 비슷하다면 그 방법과 어떤 부분에서 독창적인 연구를 했는지 설명이 필요한 듯..
4.3. Loss Function
세 가지 타입의 loss fuction을 사용한다.
- binary cross-entropy loss(BCE)
- edge loss
- IoU loss
$L_{h} = l_{bce}+l_{iou}$ : high-level large-field contextual feature를 위해 BCE와 IoU loss를 혼합하여 사용했다.
이는 유리 탐지를 위한 high-level cues를 찾도록 강제한다.
$L_{l} = l_{bce}+l_{edge}$ : glass map과 깔끔한 경계를 예측하기 위해 low-level cues가 필요하다.
그래서 BCE와 edge loss를 혼합하여 사용했다.
$L_{f} = l_{bce}+l_{iou}+l_{edge}$ : 최종 아웃풋으로 명확한 유리 부분의 경계가 요구된다.
따라서 세 타입의 loss function을 모두 조합한다.
최종적인 loss fuction은 다음과 같다.
$$LOSS = w_{h}L_{h} + w_{l}L_{l} + w_{f}L_{f}$$
각각의 $w$는 밸런싱 파라미터다.
5. Experiments
5.1.1 Experimental Settings
- 이미지 416 x 416
- multi-level feature extractor의 파라미터는 사전학습된 ResNeXt101 사용. 나머지는 랜덤 파라미터.
- SGD 사용. 모멘텀 0.9, 웨잇 디케이 $5 * 10^{-4}$, 200 에포크
5.1.2 Evaluation metrics
5개 사용
- IoU
- pixel accuranct(PA)
- MAE
- $F_{\beta}$
- balance error rate(BER)
5.2. Comparison with the state-of-the-arts

GDD 데이터셋으로 비교했으며 반전 없이 GDNet 성능이 좋다고 나온다.
다른 모델은 non-glass region과 많이 헷갈렸다고 하며 GDNet은 그런 걸 잘 구분해 냈다고 함.
특이한 점은 GDnet과 유사한 mirrorNet보다 EGNet의 성능이 좋다고 나옴.
5.4. Component Analysis
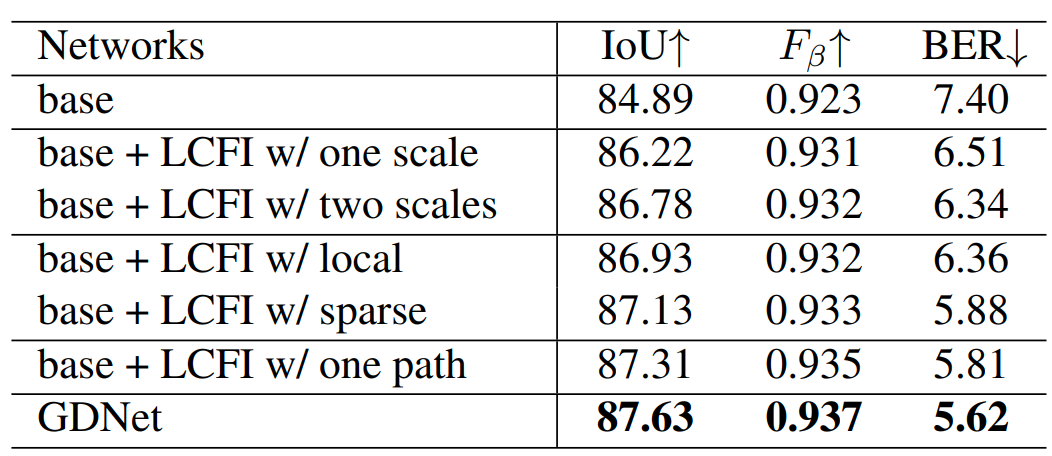

multi-scale convolution이 검출 성능을 향상해 준다는 결과를 볼 수 있다.
5.5. Mirror Segmentation

MirrorNet에 쓰인 데이터 셋을 GDNet으로 학습한 결과가 mirrorNet보다 높다고 한다.
6. Conclusion
결과에서 fail상황에 대해서 설명한다.
저자가 말한 fail 조건은 다음과 같다.
- 너무 복잡한 경우
- 유리의 바깥인지 안쪽인지 충분한 주변 정보가 주어지지 않는 경우

'연구 > 논문 리뷰' 카테고리의 다른 글
| Semantic Loop: Loop Closure With 3D Semantic Graph Matching 논문 리뷰 (0) | 2024.05.26 |
|---|---|
| Khronos: A Unified Approach for Spatio-TemporalMetric-Semantic SLAM in Dynamic Environments 논문 리뷰 (1) | 2024.04.04 |
| SP-SLAM 논문 리뷰 (1) | 2024.04.03 |
| YOLOv9 논문 요약 (6) | 2024.03.14 |
| GVINS 논문 요약 (0) | 2024.01.17 |