

수식이 틀어지는 경우, 수식에 우클릭을 하고 math setting -> math renderer -> SVG를 선택 바랍니다.
Semantic SLAM
Semantic SLAM은 semantic-level의 scene understanding이 가능하다는 점에서 이전의 방법들과 차이가 있다.
특히 고수준의 이해를 해야 하는 로봇이나 자율주행 task가 우리의 삶과 가까워질수록 더 중요해지고 있다.
아래 동영상은 visual SLAM을 연구하시는 장형기 님이 모두콘 2022에서 발표하신 Spatial AI에 대한 강연이다.
SLAM이 앞으로 발전해야 할 방향을 알기 쉽게 정리해 주셨다.
뭔가 이번 논문을 읽기에 앞서 시청하면 좋은 자료랄까.
SemanticLoop: Loop Closure With 3D Semantic Graph Matching
이 논문은 IEEE ROBOTICS AND AUTOMATION LETTERS 저널에 게재된 논문이다.
자주보는 익숙한 저널이다.
SemanticLoop: Loop Closure With 3D Semantic Graph Matching
Loop closure can effectively correct the accumulated error in robot localization, which plays a critical role in the long-term navigation of the robot. Traditional appearance-based methods rely on local features and are prone to failure in ambiguous enviro
ieeexplore.ieee.org
Journal Bibliometrics는 아래와 같다.

1. Introduction
이 논문은 semantic loop closure에 대한 연구이다.
Abstract에서는 loop closure가 왜 중요한지 말한다.
먼저 저자는 현재의 appearanced 방법은 local feature에 의존하며 모호한 상황에서 실패할 수 있다고 말한다.
예를 들면 BoW(bag of words)가 ORB-SLAM, VINS-mono 같은 알고리즘에서 좋은 성능을 보여줬지만 appearance change 상황에서 아직 해결해야 할 문제가 있다.
하지만 적어도 semantic과 geometric 구조는 apperance change에 대해 불변하다.
예를 들어 의자나 책상 같은 게 낮이나 밤, 다른 시점에서 관찰되더라도 여전히 의자와 책상이기 때문이다.
하지만 generalization problem으로 인해 종종 noise(잘못된 추론)에 시달리게 된다.
이를 위해 저자는 loop closure가 있는 RGBD 기반의 새로운 semantic mapping 시스템을 제안한다.
Main contribution은 다음과 같다.
- IoU, instance-level embedding, detection uncertainty를 linear assignment 문제로 공식화하여 object-level data association 알고리즘을 제안한다.
- instance의 semantic과 topology를 2차 배정 공식으로 결합하여 appearance change에 보다 강인한 3D semantic graph matching 방법을 제안한다.
2. Related work - Data association in semantic SLAM
2.1 semantic SLAM에서 data association에 대한 선행 연구
2.1에서는 semantic SLAM에서 data association에 대한 선행 연구에 대해 살펴본다.
특히 본 논문에서는 fusion++의 방식을 참고했다.
하지만 일반적인 nearest neighbor 방식과 다르게 아래 세 가지를 이용했다.
- incoporates IoU
- instance-level embadding
- detection uncertainty
이렇게 하여 texture less 물체, deep learning model noise, odometry drift에 더 강인한 data association이 가능해졌다.
2.1.1 SLAM ++
SLAM++은 semantic SLAM의 시초다.
주변 물체인 책상과 의자를 랜드마크로 사용했다.
Data association은 PPF(Point-Pair feature) 기반의 3D object recognition에 의존했다.
이 방식은 객체의 3D geometry를 활용해서 특징 쌍을 매칭함으로써, 환경 내의 특정 객체를 식별하고 위치를 정확하 파악할 수 있게 했다.
하지만 CAD 파일이 사전에 필요하다는 점에서 보편적이지 못하다는 단점이 존재했다.
2.1.2 Fusion++
Fusion++은 각각의 물체에 대해 TSDF volume을 빌드한다.
이를 위해서 reconstruction-by-segmentation 전략이 사용되었다.
SLAM++에서의 CAD 파일 문제를 해결했다.
그래서 영상을 보면 정말 다양한 object를 랜드마크로 사용하는 모습을 보여준다.
여기서 data association을 할 때 instance segment의 mask와 TSDF volume으로부터 예측된 mask 사이의 IoU를 이용한다.
하지만 odometry drift나 object가 겹치는 상황에서 data association 결과도 모호해지는 상황이 발생한다.
2.1.3 Probabilistic data association
- Gaussian PDA
EM(Expectation-Maximization) 알고리즘 사용을 제안하였다.
하지만 계산비용의 문제가 있었음. - Semantic MM
MM(Max-Marginalization) 알고리즘을 사용해서 Gaussian PDA에서의 계산비용문제를 해결했다.
미래의 데이터가 과거의 데이터에 영향받지 않는다는 가정을 통해 계산비용문제를 해결했다.
하지만 odometry로 인해 모호한 상황이 발생할 때, 이전의 data association을 고려하지 않아 확률 보장이 안 되는 문제점이 있었음.
2.1.4 Quadric SLAM & Cube SLAM
두 알고리즘 다 Multi-view와 2D bounding box로부터 얻은 타원체와 직육면체를 물체 표현에 사용했다.
- Quadric SLAM
Data association 문제를 간과하고 elipsoid 초기화에 집중했다. - 논문 : Semantic SLAM with Autonomous Object-Level Data Association
BoW모델을 사용해서 물체 표현에 활용하고 data association을 linear assignment 문제로 공식화했다. - Cube SLAM
특징점 매칭에 의한 data association이 이루어졌다.
따라서 특징점을 뽑기 힘든 TV와 같은 물체에 대해서 실패할 수 있다.
2.2 semantic SLAM에서 loop closure에 대한 선행 연구
2.2에서는 semantic SLAM에서 loop closure에 대한 선행 연구에 대해 살펴본다.
본 논문에서 제안하는 loop closure는 online으로 3D semantic maps를 구성하여 수행된다.
loop detection을 더 효율적으로, 강인하게 하기 위해서 다음과 같은 두 가지를 수행한다.
semantic graph 사이에 geometric graph 매칭을 수행한다.
기존의 vertices 사이에 descriptor 매칭을 하는 방법이 아님!
camera와 물체의 pose를 유지하기 위한 PGO가 포함된 완전한 파이프라인을 구성한다.
2.2.1 SLAM++
SLAM++에서는 local object graph를 long-term object graph와 매칭하여 loop closure를 수행했다.
물체를 하나의 정점으로 취급했다.
또한 PPF를 추출하기 위해 물체의 X축의 normal 방향을 사용하고 data association에 동일한 3D object recognition 알고리즘을 재사용함.
2.2.2 Fision++
3D BRISK를 추출하고 loop detection을 위해서 3D-3D RANSAC 알고리즘 사용.
하지만 GPU 환경에서도 매우 느리게 작동한다는 단점이 있음.
최근의 방법들은 더 많은 semantic 정보를 loop closure 문제에 포함하려는 시도를 하는 중이다.
2.2.3 X-view
instance segment를 해서 연속된 이미지에서 semantic 그래프를 구성한다.
연결된 semantic은 하나의 정점으로 분류되어 한 프레임 속에 여러 blobs로 구성되고 graph로 넘어가서 edge로 연결된다.
loop detection은 정점 사이의 random walk descriptor(X-view에서 제안한 방법) 매칭으로 이루어진다.
여기에서 random walk descriptor는 semantic graph의 topological 정보를 포함한다.
2.2.4 논문 Global Localization with Object-Level Semantics and Topology
이 논문은 X-view의 아이디어를 3D로 확장했다.
X-view에서 제안한 random walk는 말 그대로 랜덤이기 때문에 정보를 손실하는 경향이 있고 이는 성능 저하를 야기한다.
3. Method
세 개의 모듈이 있다.
- Semantic mapping
- graph-based loop closure
- pose graph optimization(PGO)
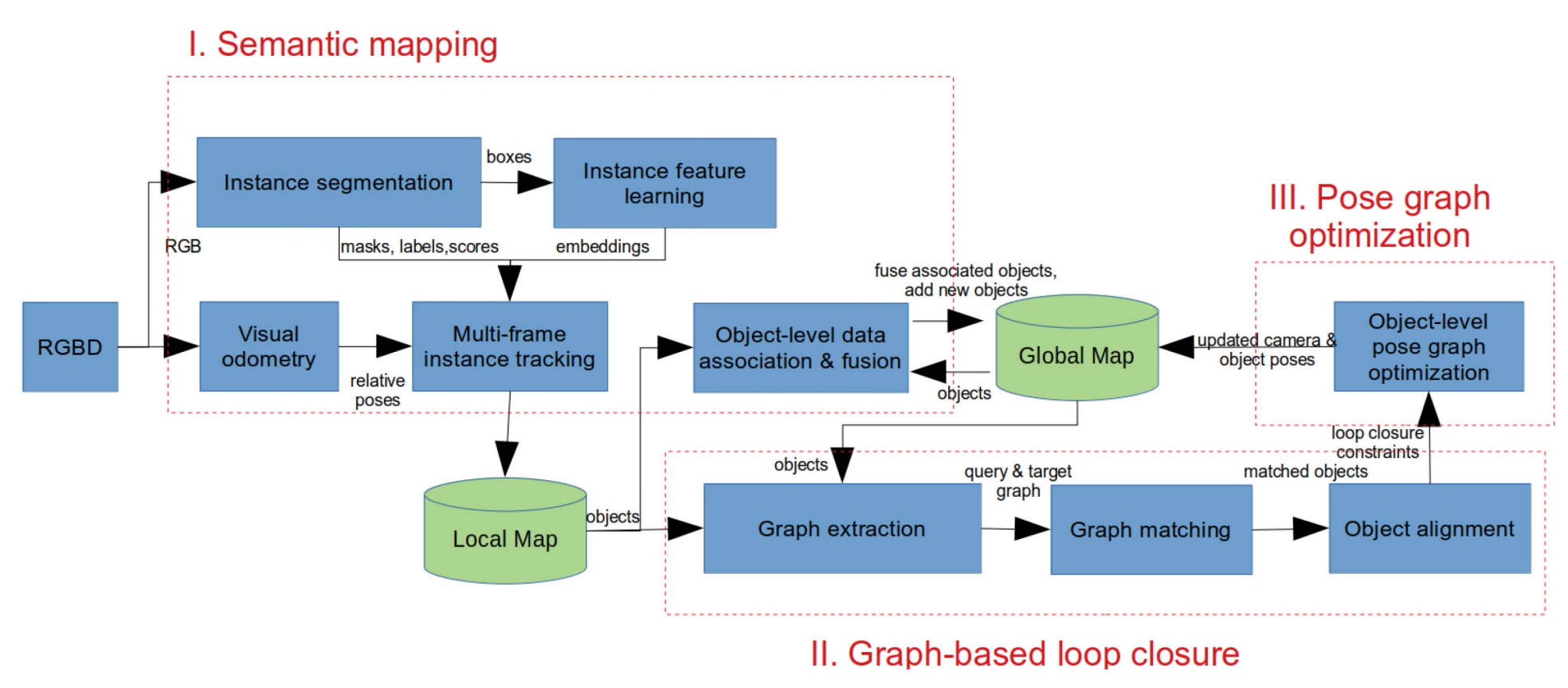
A. Semantic Mapping
RGBD이미지로 instance segmentation을 진행한다.
이때 나온 bounding box 정보는 instance feature lerning로 들어가고 instance-level embedding을 반환한다.
이렇게 뽑은 masks, labels, scores, embedding은 multi-frame instance tracking 알고리즘을 거친다.
이 알고리즘은 percepture 노이즈를 걸러내고 현재 위치에서의 local map에 통합된다.
그리고 object-level data association & fusion 알고리즘에서 camera pose와 semantic정보에 기반하여 local map의 object와 global map의 object를 매칭한다.
매칭이 없다면?
새로운 물체라고 간주하고 TSDF volume을 global map에 추가한다.
매칭이 되었다면?
Fusion++에서와 유사한 접근법으로 기존의 TSDF volume에 fuse 하고 평균화 기법을 이용해서 semantic 레이블에 대한 확률 분포를 업데이트한다.
1) Object-level data association
저자는 semantic mapping의 핵심이 object-level의 data association이라고 강조한다.
object map에
object-level association은 각 detection에 최대 하나의 객체를 할당하여 총 매칭 비용을 최소화하면서 가능한 한 많은 매치를 찾는 것이다.
일반적으로 랜드마크의 수가 detection보다 많기 때문에 (
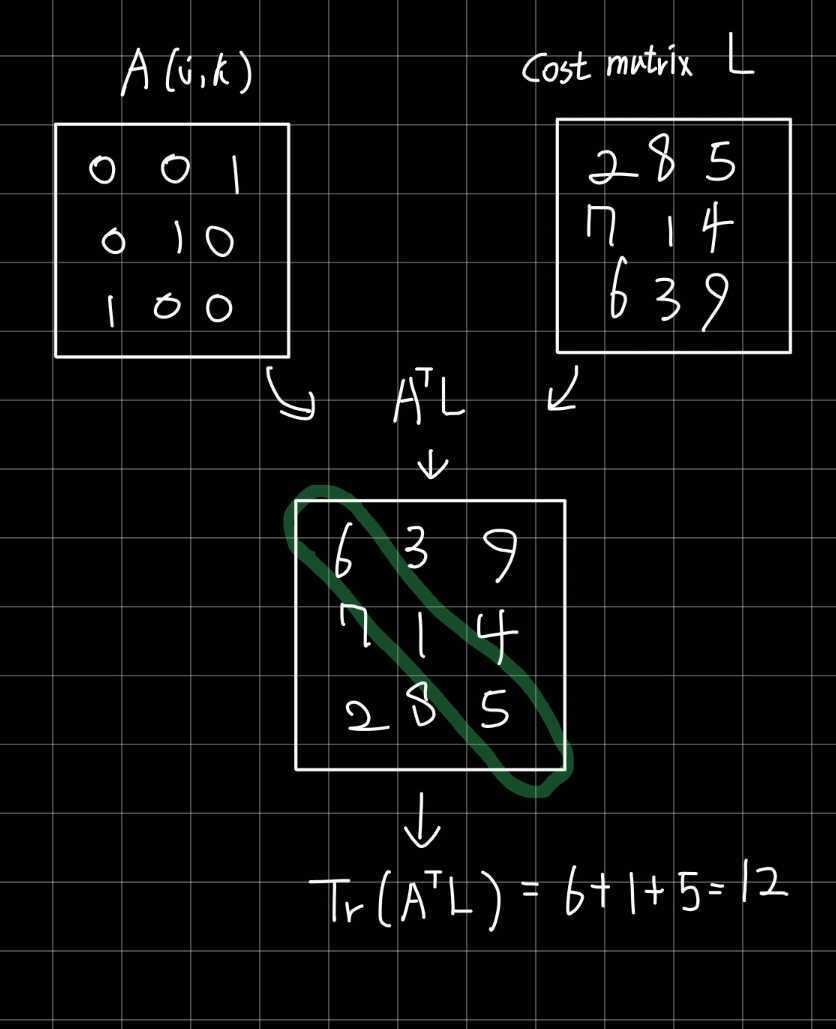
수식(1)의 그림을 그려봤는데...
행렬
Object map에 있는 object와 현재 프레임에서 찾은 object가 매칭이 된다면 1 아님 0으로 할당된다.
이걸 cost matrix인 L과 행렬곱을 하면 행렬 trace를 구하는 것만으로도 minimize 문제를 편하게 구성할 수 있다.
그리고 assignment matrix는 여러 개의 매칭을 가질 수 없다는 제약조건이 식에 있다.
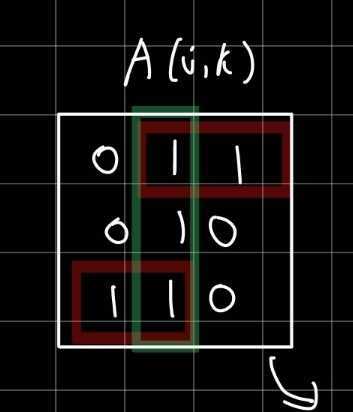
아래와 같은 경우다.
초록색, 빨간색 박스와 같이 행 또는 열에 1이 중복되면 안 된다.
그렇다면 matching cost는 어떻게 계산될까?
식은 아래와 같다.
Binary mask, instance embedding과 semantic label을 기반으로 계산한다.
이는 객체 간 매칭의 정확성을 높이는 데 사용된 것 같다.(잘못된 매칭을 줄임)
가중치
수식 (1)에서 정의한 문제는 shortest augmenting path 알고리즘을 이용한다.
이 알고리즘의 핵심은 가장 짧은 증가 경로를 찾아서 네트워크 내의 최대 플로우를 효율적으로 계산하는 것이다.
2) Multi-Frame Instance Tracking
딥러닝 모델에서 발생하는 perceptual noise를 줄이는 필터 역할을 한다.
식은 1)에서 설명한 것과 같지만, predicted mask 대신에 이전 프레임의 mask를 사용한다는 점이다.
어떤 식으로 필터링이 되는 걸까를 생각해 보면...
예를 들어 이전 프레임에서 책상과 의자가 감지되었고 이번 프레임에서도 감지가 되었다고 해보자.
하지만 이번 프레임에서 noise로 인해 predicted mask에 홀이 크게 생겼다고 하면 이는 굉장히 방해가 될 것이다.
이전 프레임의 mask를 끌어와 현재 프레임의 predicted mask와 비슷한 위치에 있고 label이 같다면 이를 이용해 noise를 감지할 수 있을 것이다.
이렇게 하면서 객체 추적의 일관성, noise 있는 예측에 대한 보정을 가능하게 하는 것 같다.
B. Graph-Based Loop Closure
그래프 기반 루프 클로저는 로봇이 주행하며 그래프 구조로 정보를 저장하다가 다시 방문한 장소를 찾으면 loop를 맺어주는 방식이다.
그래프 구조는 vertex(정점)와 edge(간선)으로 구성된다.
조만간 리뷰를 하긴 하겠지만 semantic 그래프의 vertices 간의 매칭에서 random walk를 활용한 연구가 있다.(대표적으로 2017년 X-view)
이런 random walk는 계산 시간을 줄여주긴 하지만 loss가 생기기 때문에 정보를 활용할 때 효율적이지 못하다.
그래서 저자는 다른 방법을 제안한다.
간략히 저자의 방법을 살펴보면,
- local과 global 맵에서 쿼리와 타겟 그래프를 뽑고 vertex와 edge의 유사도를 이용하여 둘 사이의 correspondances를 찾는다.
- 매치된 object들을 정렬하여 drift error를 추정한다.
아래 fig. 2를 참고.
주의! 이 논문에서는 vertex와 node를 혼용해서 쓰는 것 같다.
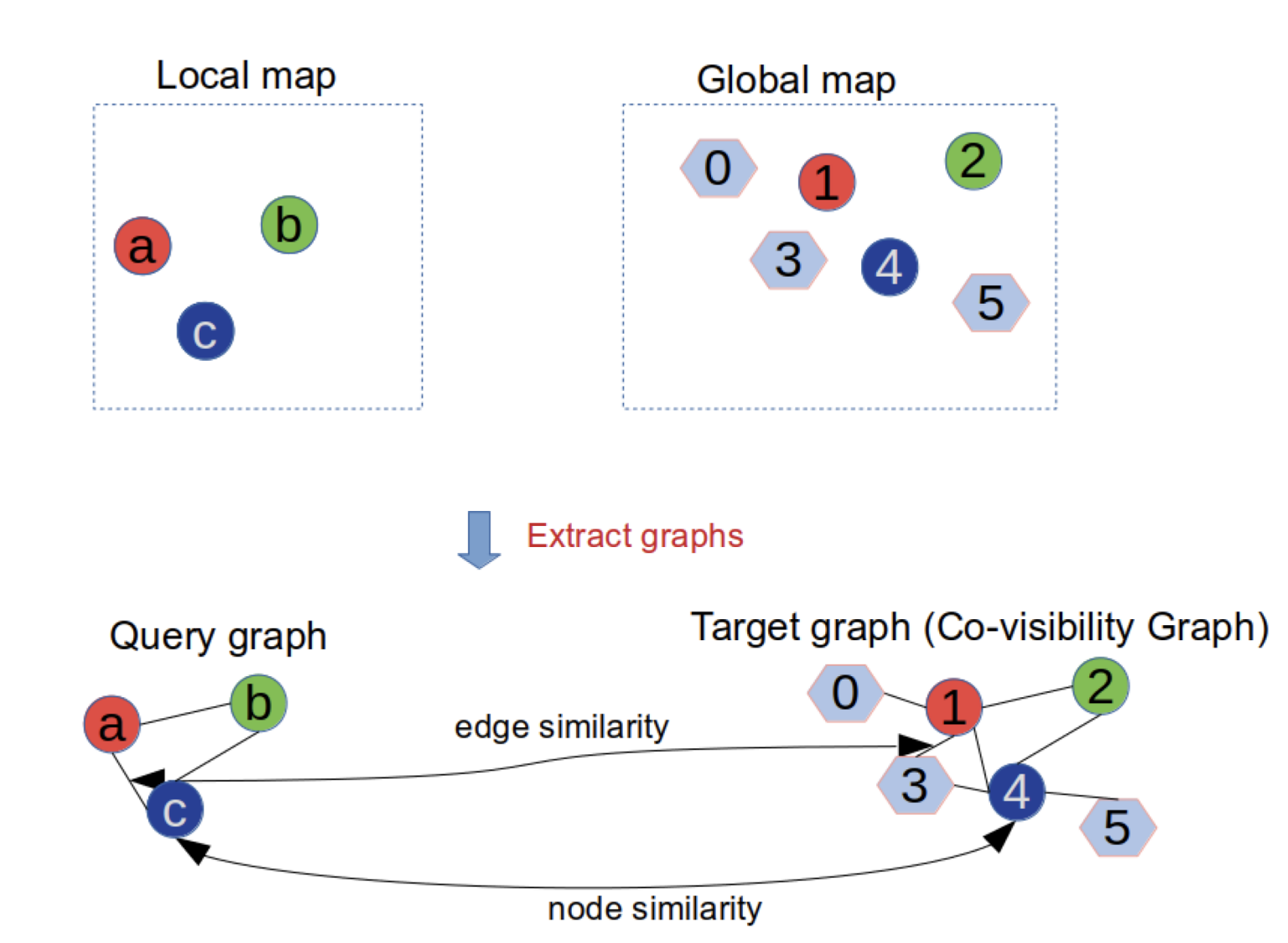
1) Graph Extraction
그래프는
Vertex
Edge
저자는 물체 사이에 topology를 유지하기 위해 co-visibility 전략을 사용했다.
co-visibility란 한글로 직역하면 공가시성이며 예를 들면 다음과 같다.
맵에 다수의 semantic object가 있을 때
현재 프레임에서 맵에 있는 일부의 semantic object를 관찰했다면,
이는 맵과 현재 프레임에서 같은 semantic object를 관찰한 co-visibility가 성립한 경우다.
이런 방법을 통해 local맵과 global맵에서 쿼리
2) Graph Matching
위에서 추출한 쿼리
이때 vertex와 graph topology 특성을 고려한다.
이것을 QAP(quadratic assignment problem)로 구성할 수 있다.
Reward matrix
제약조건은 다음과 같다.
앞서 설명했던 제약조건의 내용과 동일하다.
A행렬은 0과 1로 구성된 binary 행렬이고 행과 열에 1이 중복해서 들어갈 수 없다.
Reward matrix
따라서
계산량이 상당해 보인다.
그래서 저자는 이 문제 자체가 np-hard문제라고 말한다.
np-hard란 다항시간 내 풀 수 없는 문제를 말한다.
다음과 같은 방법을 이용하여 근사적으로 해결하는 방법을 제안했다.
- 제약조건 완화
원래 행렬 A에 대해 0과 1로만 표현되는 제약조건이 있었지만 이를 0에서 1 사이의 실수를 가질 수 있게 하면서 다루기 쉽게 했다. - 벡터화의 정규화
행렬 A를
행과 열이 중복된 1이 없으므로 하나의 벡터로 줄일 수 있다는 뜻인 것 같다. - 주성분 분석
Raleigh 비율 정리에 따르면, - Perron-Frobenius 정리
이는 각 요소가 0과 1 사이의 값을 가지게 만든다. - 이산화
최종적으로, 실수 값을 가지는
이 과정에서 greedy 알고리즘을 사용해서 적절한 행/열 합을 만족하도록 했다. - 선형 할당 문제 재사용
이렇게 이산화 된 matrix에 초기의 선형 할당 문제(수식 1번)를 재사용하고 최종 assignment matrix를 구한다.
3) Object Alignment
매칭된 물체의 TSDF로부터 추출된 포인트 클라우드를 정합하면서 상대 포즈를 추정한다.
먼저 FPFH 기반의 3D-3D RANSAC으로 초기 coarse 한 정렬을 한 후 ICP를 통해 수정해 나간다.
C. Pose Graph Optimization
Pose graph optimization(PGO)의 개념은 ALIDA님의 블로그에 쉬운 설명과 예제가 수록되어 있으니 참고하면 좋다.
[SLAM] Pose Graph Optimization 개념 설명 및 예제 코드 분석
1. Introduction 로봇이 SLAM을 수행하는 동안 센서 데이터가 입력으로 들어오는데 순차적으로 들어오는 센서 데이터들의 차이를 통해 로봇의 포즈를 계산하는 알고리즘을 Odometry 또는 Front-end 라고
alida.tistory.com
이 논문에서 제안한 pose graph는 object와 camera 노드를 둘 다 가지고 있다.
각각의 노드는 SE(3) 변환을 가진다.(rotation과 translation으로 구성된 special euclidean group)
각각의 노드에 있는 SE(3) 측정값으로 대응되는 노드 간의 상대 변환을 구한다.
카메라 노드는
object 노드는
프레임
아래의 fig. 3. 에서 방금 얘기한 내용을 한눈에 볼 수 있다.
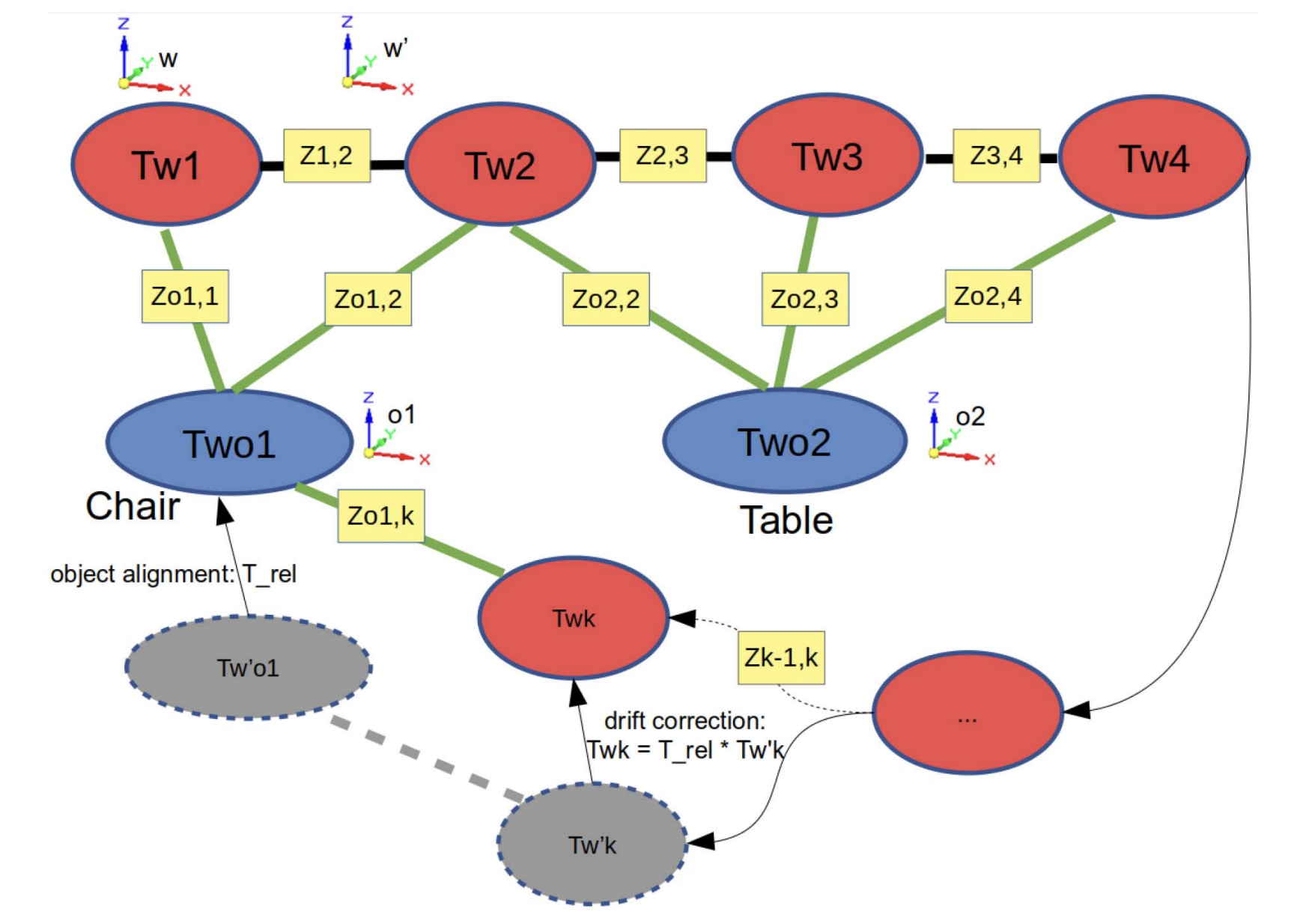
1) Object-Level Pose Graph Optimization
Object 정렬로 drift error를 알았다면, 정상적인 카메라 포즈를 알아낼 수 있고 pose graph에 object-camera 간의 새로운 제약 조건을 추가한다. (마찬가지로 위 fig. 3. 을 보면 그림으로 잘 나와있음.)
이렇게 하면 object-level의 PGO를 해서 object의 포즈와 camera의 경로를 refine 할 수 있다.
모든 제약조건의 에러항을 최소화한다.
마할라노비스 거리를 이용하면 데이터의 상관관계와 분산을 반영하여 더 정확한 거리를 계산할 수 있다.
수식의
Logarithm mapping 하여 최적화 시 파라미터 수를 줄여 계산효율을 개선한다.
Lie 대수에 관한 내용은 ALIDA님의 유튭에 영상이 있다.
이 문제를 Levenberg-Marquart(LM) 알고리즘으로 Ceres Solver 라이브러리를 이용해 푼다.
최적화된 물체의 포즈와 카메라의 경로는 새로운 물체가 추가되기 전 업데이트한다.
4. Experiments
update 예정
2024. 5. 26. 업로드
'연구 > 논문 리뷰' 카테고리의 다른 글
| Don't Hit Me! Glass Detection in Real-world Scenes 논문 리뷰 (1) | 2024.04.16 |
|---|---|
| Khronos: A Unified Approach for Spatio-TemporalMetric-Semantic SLAM in Dynamic Environments 논문 리뷰 (1) | 2024.04.04 |
| SP-SLAM 논문 리뷰 (1) | 2024.04.03 |
| YOLOv9 논문 요약 (6) | 2024.03.14 |
| GVINS 논문 요약 (0) | 2024.01.17 |